Introduction: The “Student” Computer – How AI Gets Smart
We’ve talked about how Artificial Intelligence (AI) can perform smart tasks and how Machine Learning (ML) is a way for computers to learn from data. But how does this “learning” actually happen? It’s not like a human student cramming for an exam the night before!
The process of teaching an AI system is known as “training an AI model.” It is an exciting journey from raw data to a competent, intelligent tool.
If you’re a creative or entrepreneur, learning the fundamentals of AI training will help you understand what goes into the AI tools you use, how they improve, and perhaps spark ideas for how you can employ unique AI solutions.
Don’t worry, we’re keeping this strictly non-geeky. Think of it as a peek behind the curtain of AI’s classroom.
What is an “AI Model” Anyway?
Before we talk about training, let’s quickly clarify what an AI model is. In simple terms, an AI model is like a specialized computer program that has been designed to recognize certain types of patterns or make specific kinds of decisions. It’s the “brain” that’s been taught a particular skill.
For example:
- A model for image recognition has learned to identify objects in pictures.
- A model for language translation has learned how to convert text from one language to another.
- A model for predicting sales has learned to forecast future revenue based on past data.
The model itself starts as a blank slate or an untrained student. The training process fills it with knowledge and enables it to perform its designated task accurately. Below are some examples of AI Models from Google, some of which you probably already know and use.
The Training Process: A Step-by-Step Journey
Training an AI model isn’t a single event; it’s a carefully orchestrated process. While the technical details can get very complex, the overall steps are logical.
Here’s a simplified breakdown:
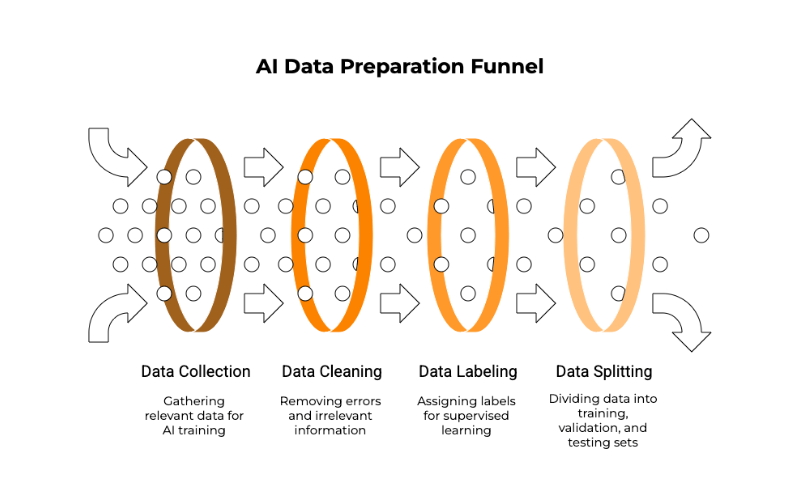
Step 1: Gathering and Preparing the Data (The Textbooks)
We see this as the most critical phase. AI models learn from data. Hence, the quality and quantity of the data are critical. Think of data as the textbooks and study materials for our AI student.
- Data Collection: First, you need to gather relevant data. If you’re training an AI to recognize cat pictures, you need thousands (or even millions) of cat pictures. If it’s for understanding customer sentiment, you need lots of customer reviews.
- Data Cleaning: Raw data is often messy. It might have errors, missing pieces, or irrelevant information. This data needs to be “cleaned” to ensure the AI learns from accurate and practical examples. It’s like making sure the textbooks don’t have torn pages or incorrect facts.
- Data Labeling (for Supervised Learning): For many types of AI training (called supervised learning), the data needs to be labeled. The AI needs to be told what it’s looking at. For cat pictures, each image would be labeled “cat.” For customer reviews, each review might be labeled “positive,” “negative,” or “neutral.” This labeling provides the “correct answers” that the AI tries to learn.
- Splitting the Data: The prepared data is usually split into three sets:
- Training Data: The most significant portion that is actually used to teach the AI model.
- Validation Data: Used during the training process to tune the model and see how well it’s learning on data it hasn’t seen before. It helps prevent the model from just “memorizing” the training examples.
- Testing Data: Used after the model is fully trained to give a final, unbiased evaluation of its performance on completely new data.
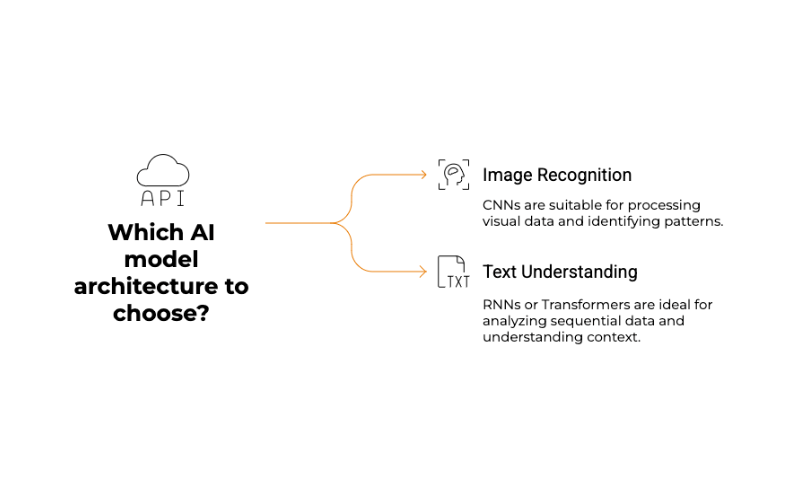
Step 2: Choosing the Right Model Architecture (The Learning Style)
There isn’t a one-size-fits-all AI model. Different tasks require different types of model architectures (the underlying structure and algorithms). For example, models for image recognition (like Convolutional Neural Networks – CNNs) are structured differently from models for understanding text sequences (like Recurrent Neural Networks – RNNs or Transformers).
Choosing the right architecture is like deciding on the best learning style or teaching method for a particular subject. Data scientists consider the problem they’re trying to solve, the type of data they have, and the desired outcome.
Step 3: Training the Model (The Study Sessions)
Here is where the actual “learning” takes place. The training data is fed into the chosen model architecture.
Here’s a simplified idea of what occurs:
- Making Predictions: The model takes input from the training data (e.g., a picture of a cat) and makes a prediction (e.g., it guesses “dog”).
- Checking the Answer: The model’s prediction is compared to the actual label (which says “cat”).
- Calculating the Error: The difference between the predicted and actual labels is measured. It is commonly referred to as the “loss” or “error.”
- Adjusting the Model: The model then adjusts its internal settings (called “weights” or “parameters”) in a tiny way to try and make a better prediction next time. This adjustment process is guided by sophisticated mathematical techniques (like gradient descent), but the core idea is to minimize the error.
- Repeat, Repeat, Repeat: This process of predicting, checking, and adjusting is repeated thousands or even millions of times, with the model going through the entire training dataset multiple times (each pass is called an “epoch”).
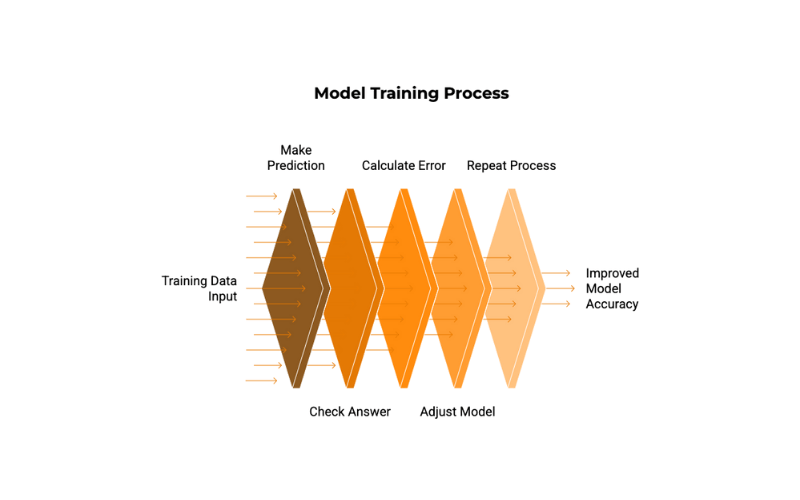
Think of it like a student practicing math problems. They try a problem, check their answer, see where they went wrong, and then adjust their understanding to do better on the following problem.
Step 4: Evaluating and Tuning the Model (The Quizzes and Feedback)
During and after the main training phase, the model is evaluated using the validation data. This helps data scientists see if the model is genuinely learning to generalize (i.e., perform well on new data) or if it’s overfitting (meaning it has memorized the training data too well but can’t handle new examples).
Based on this evaluation, data scientists might:
- Tune Hyperparameters: These are like the settings for the training process itself (e.g., how much the model adjusts its weights after each error, how many layers the neural network has). Fine-tuning these can significantly improve performance.
- Try Different Architectures: If one model isn’t working well, they might switch to a different one.
- Get More or Better Data: Sometimes, the problem is with the data itself.
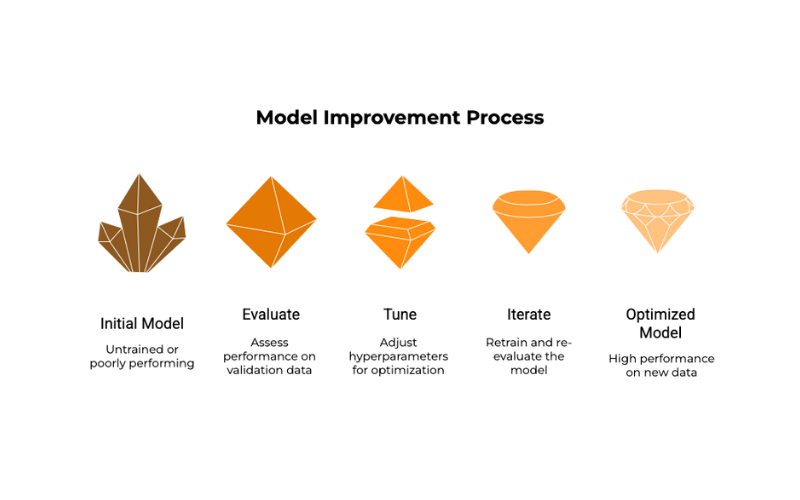
Iterative steps include training, assessing, fine-tuning, and repeating until the model performs well on the validation set.
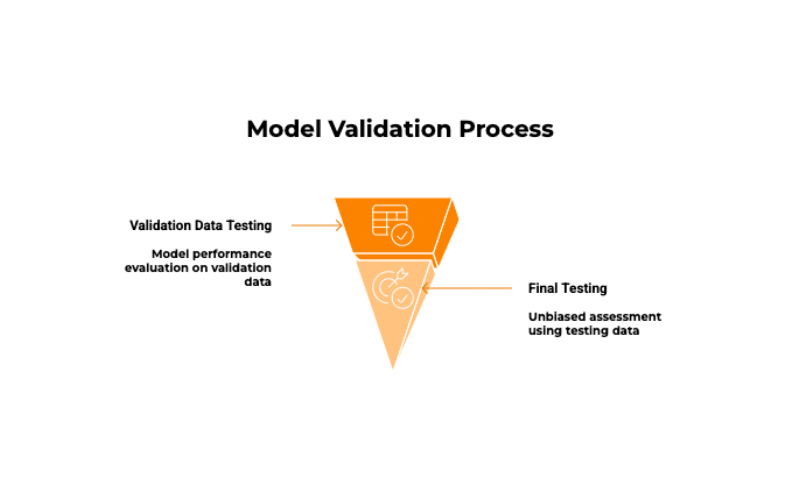
Step 5: Testing the Model (The Final Exam)
Once the data scientists are satisfied with the model’s performance on the validation data, it’s time for the final test using the testing data. This data has been kept completely separate and provides an unbiased measure of how the model is likely to perform in the real world.
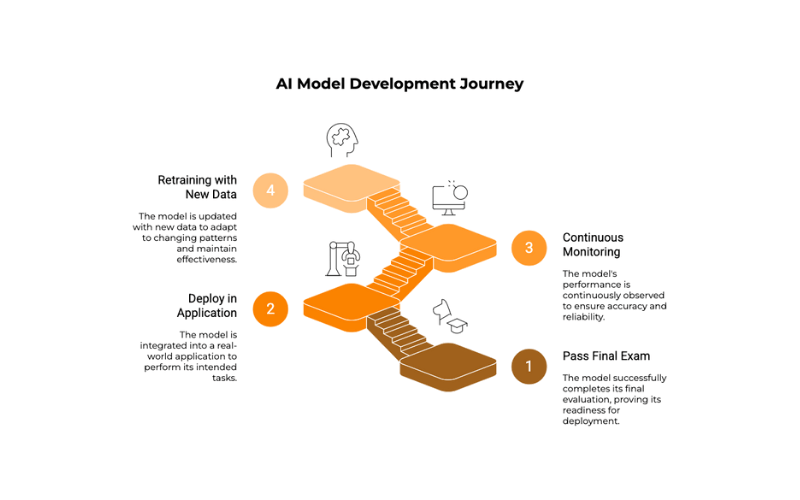
Step 6: Deployment and Monitoring (Graduation and Real-World Performance)
If the model passes the final exam, it’s ready to be deployed and put into a real application to start doing its job. But the learning doesn’t necessarily stop there. Many AI systems are continuously monitored and sometimes retrained with new data to ensure they remain accurate and adapt to changing patterns over time. It’s like ongoing professional development for AI!
Types of Learning: Not All Students Learn the Same Way
We briefly mentioned Supervised Learning (learning with labeled data). There are other essential types, too:
- Unsupervised Learning: After being presented with unlabelled data, the AI looks for patterns or structures on its own. Imagine assigning a student a stack of jumbled pictures and asking them to arrange them into groups that appear to be related without specifying which groups they should form. This is used for tasks like customer segmentation (finding groups of similar customers).
- Reinforcement Learning: The AI learns by trial and error, receiving rewards or penalties for its actions. Imagine training a dog: it gets a treat (reward) for sitting on command and a gentle correction (penalty) for not. This is how AI learns to play games (like Chess or Go) or control robots.
Why is Good Training So Important?
An AI model is only as good as its training.
- Biased Data Leads to Biased AI: If the training data reflects real-world biases (for example, if facial recognition is mostly trained on a certain demographic), the AI model will learn and reinforce such biases, which is a major ethical concern.
- Poor-quality Data Leads to Poor Performance: Garbage in, garbage out. If the data is inaccurate or irrelevant, the AI won’t learn effectively.
- Not Enough Data: Many advanced AI models, intense learning models, need vast amounts of data to learn correctly.
Conclusion: The Making of an Intelligent Assistant
Training an AI model is a sophisticated process that combines data preparation, clever algorithms, and iterative refinement. It’s about guiding a computer system to learn from examples, much like we do, but on a massive scale and with incredible speed.
As creators and entrepreneurs, knowing that AI tools have gone through this rigorous training can give you more confidence in their capabilities. It also highlights the importance of high-quality data and the ongoing efforts to make AI more accurate, fair, and valuable for everyone.

[…] What to Read Next: Explore Amazing Techniques AI Models Use to Learn: A Beginner’s Guide […]
[…] our previous “Learn AI Series” article; Explore Amazing Techniques AI Models Use to Learn: A Beginner’s Guide we explored how AI models learn. Today, let’s look at some frequent examples of AI that […]